Catching up with RL: TUD Lecture on RL #1
Why?
I want to build my RL foundations in a more systematic way both by reading literatuer and visiting the RL course at TU Darmstadt this summer term. For this purpose it's nice that I am completely done with my course work so I can focus on the thesis. This gives me the freedom to visit interesting lectures where necessary and skip the ones that I don't want to hear.
Reading List
- Reinforcement Learning: An Introduction (Sutton & Barto)
- Grokking Deep Reinforcement Learning
- Simplifying Deep Temporal Difference Learning (Gallici et al.), PQN Paper
- ...
Lecture 1: Introduction to Reinforcement Learning
What is RL?
Agent oriented learning -> learning by interacting with an environment to achieve a goal
- repeated interactions with the world (do not know in advance how the world works)
- rewards for sequences of decisions
Learning by trial and error with only delayed evaluative feedback (reward)
- the kind of ML most like natural learning
- learning can tell for itself when it is right or wrong
Typical Setting
- At every time-step the agent perceives the state of the environment
- based on this perception -> chooses an action -> receives numerical award
- find a way of choosing actions (called a policy) which maximizes the long term expected result
Success Stories
- Atari
- AlphaGo
- ChatGPT
- ...
What's Special about RL?
- Goal: learn policy that max. long term sum of rewards in unknown + stochastic env
- Assumption: "easier" to specify cost of behavior, than behavior
Core Characteristics
- no supervisor (only reward signal)
- feedback always delayed
- data is sequential, non iid
- agent's actions affect subsequent data it receives
- some more complicating factors
- dynamic environments
- stochastic dynamics and rewards
- unknown dynamics and rewards
- exploration vs. exploitation
- temporal credit assignment
Designer Choices
- Representation (how to represent the world and space of actions, ...)
- Use of Prior Knowledge
- Algorithm of Learning
- Objective Function
- Evaluation
Desirable Properties
- Convergence, Consitency, Small error, High learning speed, Safety, Stability
Restrictions / Contraints
- Compute and Time
- Data
- Online vs. offline
Introduction to Markov Decision Process (MDP)
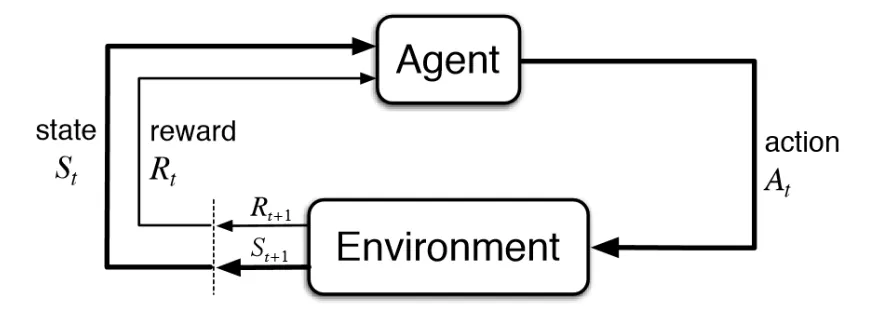
- MDPs formally describe an environment for RL
- The env is fully observable (current state completely characterizes the process)
- They allow for precise theoretical statements (e.g. on optimal solutions)
- Almost all RL problems can be formalized as MDPs
- We will focus on fully observable MDPs and finite MDPs
Stochastic Process
- An indexed collection of random variables (e.g. a time series of weekly demands for a product)
- Discrete case: At a particular time t, labeled by integers, a system is found to be exactly one of a finite number of mutually exclusive and exhaustive categories or states, labeled by integers too
The Markov Property
- "The future is independent of the past given the present"
- the state captures all the information from the history (rest may be thrown away)
- state = sufficient statistic for the future
- conditional probabilities are transition probabilities (defined by state transition matrix)
Markov Chain
- A Markov chain is a memoryless stochastic process (i.e. sequence of random states) with the Markov property.
- It models an environment in which all states are Markov and time is divided into stages
Types of Markov Processes
- Absorbing: if it has at least one absorbing state and if that state can be reached from every other state
- Ergodic: if all states are recurrent and aperiodic
- Regular: is some power of the transition matrix has only positive and stable elements
Flavors of the RL Problem
- Full RL Problem
- Partially Observable Markov Decision Problem (POMDP) -> filtered state, sufficient statistics
- Markov Decision Problem
- Further simplifications
- Contextual Bandit
- Bandit
Reading Assignment
- Sutton & Barto Chapter 1
Get in Touch
If you have any feedback you want to share with me feel free to reach out at mail@sebastianwette.de. I would be more than happy to chat about it.