TUD Lecture on RL #2
Lecture 2: Markov Decision Processes
An agent learns by interacting with its "environment". How can we formalize this?
MDPs
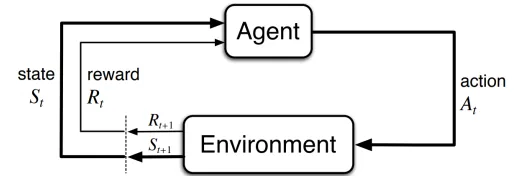
Sequence of discrete time steps = 0,1,2,...
At each step
- Receive representation of state
- Execute action
- Obtain reward and reach a new state
Sequential interaction between agent and environment generates a trajectory:
A Markov Decision Process (MDP) is a tuple where:
- is the set containing all states
- is the set containing all actions
- is the reward function
- is the transition function
- is the probability dist. over initial states
- is the discount factor
Types of MDPs
- Discrete (finite) MDP: discrete state and action space
- Continuous MDP: continuous state and discrete/continuous action space
- Deterministic MDP: det. transition function
- Stochastic MDP: stochastic transition function (probability)
The dynamics of an MDP is defined by a probability:
- Dynamics only depend on current state and executed action -> known as the Markov property
- This equation enables obtaining all info about the env. (state transition probability function and the expected reward for state-action pairs, ...)
Episodes
- Interaction between an agent and the env. is modeled through episodes
- Agent starts an episode in one of the possible inital states
- Episode ends when the agent has performed a max. number of steps ("horizon") OR the agent has reached an absorbing state (e.g. game over in a Atari game).
- Episodes are used to train agents and evaluate their behavior
Returns
A Return is the sum of rewards collected after T steps
- Usually computed over whole episode
- Using the discount factor one can calc. the "discounted return" (it is mathematically convenient to discount rewards + it avoid infinite returns in cyclic MDPs)
The goal of RL is obtaining behavior that max. the discounted return starting from any time step. Thus the reward function expresses desired/undesired behavior that should be reinforced/avoided (is designed by a human expert)
- Reward functions where reward often changes are called dense
- Reward functions where reward is almost constant are called sparse 8e.g. always 0 except for 1 upon reaching a goal state
Goals and rewards
- Is a scalar reward an adequate notion of purpose? Sutton hypothesis: all of what we mean by goals and purposes can be well thought of as the max. of the cumulative sum of a received scalar signal (reward).
- A goal should specify waht we want to achieve and not how we want to achieve it. The same goal can be specified by infinite different reward functions.
- The agent must be able to measure success explicitly and frequently
Policies and value functions
- What do we mean by behavior of an agent? -> A policy is a proba. dist. that, givan a state computes the proba. of executing any action from that state. Commonly denoted as
- RL aims at obtaining the policy that maximizes the return obtained from any state -> called "optimal policy", denoted as
Value function
The value function of a state under a policy is the expected discounted return when starting in and following :
The action value function of taking an action in state under a policy is the expected discounted return when starting in executing and following :
The value functions induced by an optimal policy are called optimal value functions (optimal value functions can be used to compute optimal policies)
- There is always a deterministic optimal policy for any MDP
Bellman Equations
The following equation is known as the Bellman (expectation) equation:
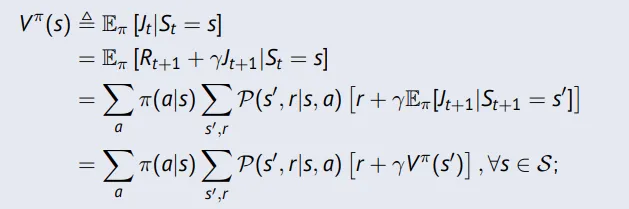
Can be expressed concisely using matrices
- is a linear equation and can be solved directly (only possible for small MDPs with Gaussian elimination or iterative solutions)
- there are many iterative methods for large MDPs: Dynamic Programming, Monte-Carlo RL and Temporal Difference Learning
Bellmans principle of optimality
- An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision.
Further reading and supplementary material
- Sutton & Barto Chapter 3
- This Video-Lecture on MDPs